
郭栩宁* 李坦 周彦丽 李彤彤
天津师范大学教育学部
1752519160@qq.com
【摘要】 本研究基于中国大学MOOC平台构建课程交互文本分析模型。构建基于Bi-LSTM和Self-Attention的情感分析模型实现课程评论文本的情感分析,为相关学习者课程选择提供依据;并采用基于Relevance公式的LDA文本主题挖掘模型挖掘课程讨论文本潜在的重要主题,有利于教学者优化教学内容和教学方法。
【关键词】 MOOC、交互文本、情感分析、主题挖掘
Abstract: Based on the MOOC platform of Chinese universities, this study constructs the interactive text analysis model of courses. This paper constructs the emotion analysis model based on Bi LSTM and self attention to realize the emotion analysis of the course review text, and provides the basis for the relevant learners to choose the course; The LDA text topic mining model based on relevance formula is used to mine the potential important topics of the course discussion text, which is helpful for the teachers to optimize the teaching content and teaching methods.
Keywords: MOOC, Interactive text, Emotion analysis, Topic mining
1.前言
教育部印发《2019年教育信息化和网络安全工作要点》中强调持续推进高等教育资源建设。学习者在参与型开放式网络课程(Massive Open Online Courses,MOOC)因开放性、共享性以及自主性等吸引了众多学习者,打破了时间和空间的限制,推动传统教育教学模式进行转变,为教育教学注入了新的活力。新冠肺炎疫情爆发时期,教育部“停课不停学”的教育决策为其融入主流教育体系提供了新机遇。但当前的MOOC教育面临着一个重大难题,学习者在面对质量参差不齐的海量课程,难以选择合适的课程完成学习,导致参与率和完成率不高(Koller, 2012)。MOOC课程学习过程中产生的交互文本数据,真实地反映了学习者在学习过程中的状态。本研究对不同性质的课程交互文本数据进行情感分析和主题挖掘,以期为学习者课程选择提供可靠依据以及为教学者优化教学提供可行建议。
2.研究综述
目前,在线课程评论文本的相关研究相对较少,但已有学者提出基于课程评论文本有效评估和提升MOOC课程教学质量,运用文本挖掘方法对在线课程文本内容进行深度挖掘。文本挖掘可自动对大量评论内容进行分类和情感检测,减少研究者主观意志带来的干扰和误差,使结果更加准确和安全。当前文本挖掘主要包括文本主题挖掘和文本情感分析两大类(曾宁、张宝辉和范逸洲,2019)。在文本主题挖掘方面,刘三女牙等(刘三女牙、彭晛等,2017)应用LDA模型自动挖掘不同类型学习者之间话题分布的特征结构和语义内容,探究学习者类型与话题空间分布的映射关系和热点话题的演化趋势,为调整在线教学方法和提升学习体验服务提供建议。在文本情感分析方面,单迎杰等(单迎杰和傅钢善等,2021)发现积极的情感体验占比较大,慕课中期阶段消极情感体验最多。张新香等(张新香和段燕红,2020)利用BTM模型提取学习者评论主题,基于情感词典计算主题情感值,采用灰色关联分析评判MOOC质量。也有研究将情感分析和主题挖掘结合起来实现课程交互文本挖掘。田娜等(田娜、周驿和严蓉,2020)采用 LDA主题模型建模和情感分析方法,探索学习者的关注话题以及话题情感倾向,发现学习者对课程学习资源存在不满。主题挖掘和情感分析均是实现课程交互文本挖掘的有效途径,但目前大多研究更侧重于使用一种方法进行课程交互文本的分析,本研究根据中国大学MOOC平台中不同类型的课程交互文本特性,采用主题挖掘和情感分析两种文本分析手段,构建课程交互文本分析模型。其中包含构建基于Bi-LSTM和Self-Attention的情感分析模型实现课程评论文本情感分析;采用基于Relevance公式的LDA文本主题挖掘模型挖掘课程讨论文本潜在的重要主题。
3.课程交互文本分析模型
中国大学MOOC是国内优质的中文MOOC学习平台,现已推出了两千多门课程, 涉及基础学科、工程技术和文学艺术等多个学科领域(赵磊、吴卓平等,2017),为国内学习者在线学习提供丰富的资源。中国大学MOOC开设了实时讨论区,学习者在观看教学视频的过程中可以根据学习的具体内容进行提问和交流,有效促进学习者、教学者和学习内容之间的交互,形成了课程讨论文本的数据。教学者可以通过挖掘课程讨论文本数据的主题深入了解学生需求,对学生进行有效的学习指导。同时有利于教学者对自身的教学活动进行调整,更好地优化和改革教学内容和教学方法。与此同时,中国大学MOOC开设了课程评价区,课程评论区主要收集学习者的课程评价数据,课程评价数据是学习者对课程整体的主观性评价,分析评价文本蕴含的情感倾向,可以直观地反映出学习者对该课程的教学内容和教学质量的满意程度,给其他学习者提供是否选择该门课程学习的依据。
本研究基于中国大学MOOC平台构建的课程交互文本分析模型如图1所示,采集中国大学MOOC平台某门课程的课程评价区文本数据以及课程讨论区文本数据。采用构建基于Bi-LSTM和Self-Attention的情感分析模型,以一条评论文本为单位实现课程评论文本的情感分析,将课程评论文本划分为“正性”、“中性”、“负性”三种情感倾向。采用构建基于Relevance公式的LDA文本主题挖掘模型,挖掘课程讨论文本的重要主题。

图 1 基于中国大学MOOC平台的课程交互文本分析模型
3.1.数据采集与处理
本研究选取中国大学MOOC平台热度较高的国家精品课程《Python语言程序设计》作为研究对象,通过python代码实现该门课程的课程评论文本和课程讨论文本的采集,获取到包含用户ID、评论内容、评论时间等内容。在数据处理阶段,用户评论以结构化的形式保存,删除缺失数据、无关数据和异常数据,最终获得有效课程评论文本29839条,课程讨论文本1500条,将清洗后的数据用CSV格式文件存储。
3.2.基于Bi-LSTM和Self-Attention的情感分析模型

图2 基于Bi-LSTM和Self-Attention的情感分析模型
该模型由向量表示层、Bi-LSTM层、Self-Attention层以及输出层等组成。向量表示层采用本课题组开源的预训练词向量Word2Vec模型(李坦,2020),对分词后的课程评论文本实现向量编码,通过300维向量表示一个汉语词语。
Bi-LSTM层主要通过Bi-LSTM算法对课程评论文本的上下文关系和特征进行学习,Bi-LSTM算法是建立在长短时记忆神经网络(LSTM)算法基础上的,LSTM算法由输入门、遗忘门以及输出门组成,具体算法如下:

其中ht为LSTM算法t时刻细胞状态的输出值,在Bi-LSTM在t时刻的输出Ht可以表示为:

Self-Attention层是在Bi-LSTM层基础上进一步学习句子内部语义关系,相较于传统Attention算法,Self-Attention算法以句子内部词语作为查询条件,所以可以学习到句子内部语义关系,具体算法如下:

输出层是在编码和特征学习基础上,基于Softmax函数对学习者课程评论文本情感类型进行概率计算,将概率值最大的情感类型作为该文本的情感类型输出。
3.3.基于Relevance公式的LDA文本主题挖掘模型
文本挖掘是指从海量文本数据中抽取知识的过程,利用获取的知识高效组织信息(Berry, 2008)。主题模型是文本挖掘的重要工具,能够识别文档主题,挖掘语料中的隐含信息。当前常用的主题模型主要有PLSA(probabilistic latent semantic analysis)和LDA(latentdrichlet allocation),PLSA(Hofmann, 1999)是基于最大似然和产生式模型的概率模型,Blei等(Blei, Ng, &Jordan, 2003)在PLSA的基础上加入了Dirichlet先验分布,提出了隐含狄利克雷主题模型(Latent Dirichlet Allocation,LDA),该模型是基于“文档-主题-词语”的三层贝叶斯模型,运用概率方法对模型进行推导,寻找文本集的语义结构,实现文本主题的挖掘。
本文采用基于Relevance公式的LDA文本主题挖掘模型完成课程讨论文本的主题挖掘。LDA主题挖掘中最重要的环节是主题数K的选取及确定过程。Blei(Blei, Ng, &Jordan, 2003)等人认为困惑度指标可以实现最优模型的预测,选取最小的困惑度确定主题的最优数目。LDA主题模型的困惑度计算公式如下:

其中,D表示语料库中的测试集, 共M篇文档, Nd表示每篇文档d中的单词数,wd表示文档d中的词,p(wd)表示文档中词wd产生的概率。
但是根据困惑度选取的主题数目往往偏大, 从而导致抽取的主题之间相似度较大,存在主题辨识度不高的问题。Michael等人(Michael, Andreas, &Alexander, 2015)则提出使用主题一致性来度量主题的可解释性, 高一致性的主题能更贴近人们的主观认知。本研究结合LDA模型的困惑度和一致性来选取主题数K,完成最优主题模型的构建。
同时采用交互式可视化系统LDAvis将主题识别结果映射到二维空间中,揭示主题—主题、主题—词语之间的关联,通过调节参数λ(0 ≤λ≤ 1)来控制主题—词语关联度relevance, 控制显示某一主题的不同的下位词项。参数λ计算方法如下列公式(Sievert & Shirley, 2014)所示:

其中,w表示主题词,w∈{ 1,2,3,…,V };k表示主题,k∈{ 1,2,3,…,K} ; φkw表示主题词w与主题k的相关度; pw表示主题词w的分布概率。λ是一个在[0, 1]取值的可变参数,λ趋近于0时,表示主题表征词具有排他性(即在该主题下更独有、更特殊的词与主题的相关性越强);λ趋近于1时,表示在该主题下出现频率越高的词越能表征该话题。通过调整λ值,调节词语w与主题k的相关程度,完成最优主题模型的主题表征词抽取,实现课程讨论文本的主题挖掘。
4.研究结果
4.1.课程评论文本情感分布
本研究采用基于Bi-LSTM和Self-Attention的情感分析模型对每条课程评论文本内容进行“正性”、“中性”、“负性”情感类型概率计算,将概率值最大的情感类型作为该文本的情感类型输出。情感类型的数值如图3所示,情感类型的占比如图4所示。
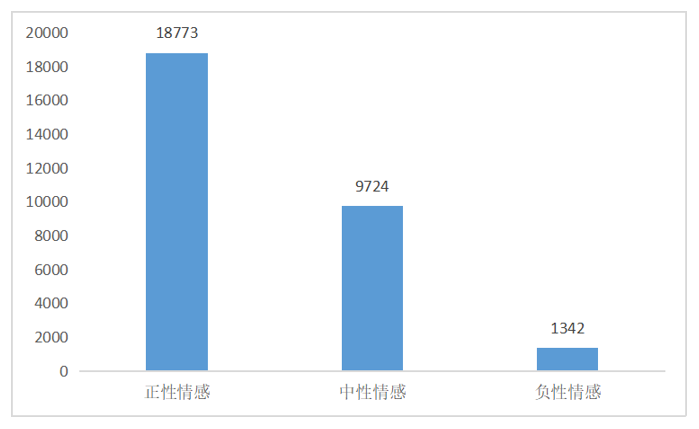
图 3 情感类型数值

图 4 情感类型占比
研究对象的有效课程评论文本共有29839条,正性情感倾向的课程评论文本18773条,占比62.91%;中性情感倾向的课程评论文本9724条,占比32.59%;负性情感倾向的课程评论文本1342条,占比4.50%。
4.2.课程讨论文本主题提取
本研究通过计算LDA模型不同主题数的困惑度和一致性,进行可视化分析后困惑度和一致性如图3、图4所示:

图 5 LDA模型困惑度

图 6 LDA模型一致性
结合两者的结果可知主题数为3和7时一致性较高,而困惑度随着主题数的递增而降低。我们结合交互式可视化系统LDAvis获取主题数为7和主题数为3的结果选取最佳主题数。
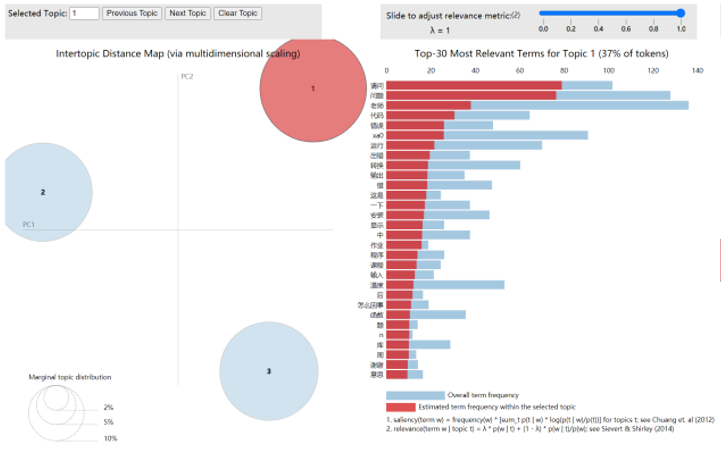
图 7 主题数为3的主题挖掘结果

图 8 主题数为7的主题挖掘结果
通过图5和图6可知,LDAvis可视化工具直观地显示出不同主题在二维向量空间上的距离,不同圆圈代表不同的主题,其大小代表主题包含文本的数量,具体代表主题之间的关联。图5中的3个主题间具有明显的差别,而且没有交叠。主题1、主题2、主题3的距离中心位置均较分散且平均。这一数据结果表明,指定的3个主题类别结果比较理想。而图6中的7个主题间存在交叠,部分主题的关联性较强。通过比较确定主题数设置为3时本研究中的LDA主题模型为最佳模型。
通过λ参数设置调整主题和词语的关联度relevance,以确定某一主题中的词汇更加符合对该主题的描述。在主题数设置为3的前提下,经过多次试验确定λ参数为0.62,LDA主题模型通常会利用高频关键字实现主题的描述,为确保主题描述的全面性,本文参照以往研究(金占勇、田亚鹏和白莽,2019)将主题输出关键字数量设为30。
本研究利用3个主题获取的关键词追溯原始的讨论文本数据,对主题含义进行描述中发现,3个主题主要可以概括为学习者在学习的过程中遇到困难向老师求助,希望老师能帮助自己解决问题。主题1描述的是学习者处于python基础语法学习阶段遇到的问题,例如“教材”、“安装”、“输出”等涉及到课程起始阶段教材的选择、运行环境的安装和程序运行程序输出等比较基础的问题。主题2中的主要关键词大部分涉及到课程的第四周学习内容“程序的控制结构”和第五周学习内容“函数和代码复用”,这两周的学习内容从python基本语法学习转向编程语言思维学习,没有编程基础的学习者会存在一定的学习难度,因为不仅需要模仿运行代码,更重要的是需要理解和使用代码解决问题。主题3中主要涉及到“温度转换”问题,学习者在运行“温度转换”程序代码时出现错误,通过对比课程内容发现,“温度转换”是课程第一周的初始学习内容,主要学习目标是掌握python的基本语法元素。但由于大部分学习者是第一次接触python语言,对python的基础语法没有基于知识,且无法自行看懂运行过程中系统的反馈错误,因而在讨论区有较多学习者针对“温度转换”进行提问,追溯原始课程讨论区文本发现,“温度转换”程序出现错误的原因主要是学习者没有区分标点符号的中英文状态。
5.研究总结
本研究根据中国大学MOOC平台中不同类型课程交互文本的特性,采用主题挖掘和情感分析两种文本分析手段,构建课程交互文本分析模型。在该模型中,采集课程评论文本和课程讨论区文本两种不同类型的课程交互文本。构建基于Bi-LSTM和Self-Attention的情感分析模型实现课程评论文本情感分析,发现《Python语言程序设计》课程评论文本中正性情感占比62.91%,中性情感占比32.59%,负性情感占比4.50%。反映出学习者对《Python语言程序设计》课程的教学内容和教学质量的满意程度呈积极情感倾向,为其他学习者选择该门课程提供依据。采用基于Relevance公式的LDA文本主题挖掘模型挖掘课程讨论文本潜在的重要主题,过程结合LDA模型的困惑度和一致性选取最佳主题数,并采用LDAvis调整主题和词语的关联度relevance,确定符合对主题描述的词汇。利用主题关键词来追溯原始数据,对主题含义进行描述过程发现,挖掘的3个主题可概括为学习者在学习的过程中遇到困难向老师求助,希望老师能帮助自己解决问题,符合中国大学MOOC平台设置讨论区的目的:深入了解学生需求,对学生进行有效的学习指导。其中主题1和3都涉及学习者初级阶段中程序运行环境的配置、基础语法出错等基础性问题,本研究建议教学者可以为学习者提供详细的学习资源或者为学习者提供相关的外部操作资源链接。主题2涉及的学习内容从python基本语法转向更结构化的语言思维,没有编程基础的学习者存在学习难度。这个过程不仅需要模仿运行代码,更重要的是需要理解和使用代码解决问题。建议教学者在学习资源的设计中不仅是代码的讲解,更需要深入浅出的教学策略帮助学习者理解代码背后的含义。
目前本研究存在一定的局限性,由于选取的课程连接性紧密,课程讨论文本本身存在的问题答疑性比较强,在主题挖掘中部分关键词的区别并不明显,导致主题描述过程存在一定难度;其次,本研究仅选取中国大学MOOC平台的《Python语言程序设计》课程作为研究对象,后续需结合更多的课程类型进一步研究。优化本研究提出的课程交互文本分析模型,满足MOOC交互文本数据分析的需求。
参考文献
田娜和周驿(2020).基于MOOC课程评论的话题挖掘与情感分析研究.软件导刊(08),19-23.
刘三女牙、彭晛等(2017).面向MOOC课程评论的学习者话题挖掘研究.电化教育研究(10),30-36.
张新香和段燕红(2020).基于学习者在线评论文本的MOOC质量评判——以“中国大学MOOC”网的在线评论文本为例.现代教育技术(09),56-63.
金占勇、田亚鹏和白莽(2019).基于长短时记忆网络的突发灾害事件网络舆情情感识别研究.情报科学(05),142-147+154.
单迎杰、傅钢善等(2021).基于反思文本的慕课学习情感体验特征分析.电化教育研究(04),53-60+75.
赵磊、吴卓平等(2017).中国慕课项目实践现状探析——基于12家中文慕课平台的比较研究.电化教育研究(09),41-48.
曾宁、张宝辉和范逸洲(2019).如何分析慕课论坛中的数据:六大分析方法述评.现代远距离教育(06),87-96.
Berry, M.(2008). Castellanos M. Survey of text mining II: Clustering, classification, and retrieval. New York: Springer.
Blei, D., Ng, A., &Jordan, M.(2003). Latent Dirichlet Allocation. Journal of Machine Learning Research, 03, 993-1022.
Hofmann, T.(1999). Probabilistic latent semantic indexing. Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, ACM, 1999. 50-57.
Koller, D.(2012). MOOCs on the move: How coursera is disrupting the traditional classroom. https://knowledge.wharton.upenn.edu/article/moocs-on-the-move-how-coursera-is-disrupting-the-traditional-classroo/.November7,2012,Knowledge@ Wharton Podcast.
Michael, B., Andreas, B., &Alexander, H.(2015). Exploring the space of topic coherence measures. Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, ACM, 2015. 399-408.
Sievert, C., &Shirley, K.(2014). LDAvis: a method for visualizing and interpreting topics. Proceedings of the workshop on interactive language learning. Baltimore: Association for Computational Linguistics, 2014. 63-70.